On a bike ride with the Missoula 55-Plus group (I'm 50, but my wife is a bit older, so I get invited to these things 😊 ), I met Mark, who runs a research laboratory here in town. His employer productizes lab tests for infectious diseases into field test kits similar to the COVID test kit so that fewer people in poor countries die needlessly for want of testing. At some point in our chat, he mentioned that his company's hiring pipeline almost completely dried up during and after the pandemic. He said that pre-pandemic they would publish an ad in places where recent biochemistry program graduates would see it and very reliably get over 100 applicants, and post-pandemic they would publish the same ad in the same venues and get closer to 10 applicants. I asked if anybody there had done any research to figure out why. They hadn't. I figured this would make a pretty interesting small-scale research project, and so I spent a few hours seeing what I could turn up on my own. I figured for this, I could sample a subset of the larger area of interest (recent biochemistry graduates) by looking at a California school (Mark's company's headquarters is in Los Angeles) and so I chose U.C. Davis.
LinkedIn Sales Navigator (LISN) makes it easy to search for U.C. Davis graduates, but it does not have a filter for when they graduated. However, this page that you don't even need a special LinkedIn subscription to view does provide what I wanted: https://www.linkedin.com/school/uc-davis/people/?educationEndYear=2022&educationStartYear=2018&keywords=Biochemistry. It allows a keyword search for the program and an actual filter for Start and End years, which is good enough for what I'm trying to do here.
That page plus a Browserflow script to get through the infinite scroll plus this Claude-generated Tampermonkey script yielded 912 LinkedIn profile URLs.
// ==UserScript==
// @name Extract Univeristy Graduates
// @namespace http://tampermonkey.net/
// @version 1.3
// @description Extracts LinkedIn profile URLs from this sort of LinkedIn search results page: https://www.linkedin.com/school/uc-davis/people/?educationEndYear=2022&educationStartYear=2018&keywords=Biochemistry
// @author You
// @match *://www.linkedin.com/*
// @grant none
// ==/UserScript==
(function() {
'use strict';
function createButton() {
// Remove ALL possible duplicate buttons
const existingButtons = document.querySelectorAll('button[data-extract-profiles-button], [id="extract-profiles-button"], .extract-profiles-button');
existingButtons.forEach(button => button.remove());
// Also remove any buttons that match our text content
document.querySelectorAll('button').forEach(button => {
if (button.textContent === 'Extract LinkedIn Profiles') {
button.remove();
}
});
const button = document.createElement('button');
// Add multiple identifiers to ensure we can find it later
button.setAttribute('data-extract-profiles-button', 'true');
button.id = 'extract-profiles-button';
button.className = 'extract-profiles-button';
button.textContent = 'Extract LinkedIn Profiles';
// Enhanced styling
Object.assign(button.style, {
position: 'fixed',
bottom: '20px',
right: '20px',
zIndex: '2147483647', // Maximum possible z-index
padding: '30px',
fontSize: '18px',
backgroundColor: '#39FF14',
color: 'black',
border: 'none',
borderRadius: '5px',
cursor: 'pointer',
boxShadow: '0 0 10px #39FF14',
fontFamily: 'Arial, sans-serif',
pointerEvents: 'auto',
display: 'block',
margin: '0',
textAlign: 'center',
userSelect: 'none'
});
button.addEventListener('click', extractProfiles);
// Only append to document.body if it exists and button isn't already present
if (document.body && !document.querySelector('[data-extract-profiles-button]')) {
document.body.appendChild(button);
}
}
function extractProfiles() {
const profileLinks = document.querySelectorAll(
'.org-people-profile-card__profile-title a[href*="/in/"], ' +
'a.app-aware-link[href*="/in/"], ' +
'.profile-card__name a[href*="/in/"]'
);
const profileUrls = new Set();
profileLinks.forEach(link => {
const href = link.href;
if (href) {
try {
const url = new URL(href);
const match = url.pathname.match(/\/in\/[^/?]+/);
if (match) {
const cleanUrl = 'https://www.linkedin.com' + match[0];
profileUrls.add(cleanUrl);
}
} catch (e) {
console.error('Error processing URL:', href, e);
}
}
});
const urlList = Array.from(profileUrls).sort();
const resultText = urlList.join('\n');
if (urlList.length === 0) {
alert('No LinkedIn profiles found. Check if you are on a page with profile cards.');
return;
}
navigator.clipboard.writeText(resultText)
.then(() => {
alert(`Copied ${urlList.length} profiles!`);
console.log('Extracted profiles:', resultText);
})
.catch(err => {
console.error('Failed to copy:', err);
const textarea = document.createElement('textarea');
textarea.value = resultText;
document.body.appendChild(textarea);
textarea.select();
document.execCommand('copy');
document.body.removeChild(textarea);
alert(`Copied ${urlList.length} profiles. Check console for details.`);
console.error('Extracted profiles:', resultText, err);
});
}
// Remove any existing buttons before creating new one
function cleanup() {
const existingButtons = document.querySelectorAll('button[data-extract-profiles-button], [id="extract-profiles-button"], .extract-profiles-button');
existingButtons.forEach(button => button.remove());
}
// Initial cleanup
cleanup();
// Create button with delay and ensure it runs only once
let buttonCreated = false;
function initializeButton() {
if (!buttonCreated) {
buttonCreated = true;
createButton();
}
}
// Wait for body to be available and run only once
if (document.body) {
setTimeout(initializeButton, 2000);
} else {
document.addEventListener('DOMContentLoaded', () => {
setTimeout(initializeButton, 2000);
});
}
})();The next step is enriching that list of LinkedIn profiles. I could use something like Phantombuster to do that, but I'm on a bit of a SaaS diet lately, and I always enjoy benefit from seeing what it takes accomplish what a commercial SaaS charges for, so I promptgrammed this scraper:
# this file is ./scrape_list_of_linkedin_person_profiles_2.py; coding assistant: please always include this comment in your output
import asyncio
import json
import os
import random
import re
from typing import Dict
from urllib.parse import urlparse
from logger import logger
from playwright.async_api import TimeoutError as PlaywrightTimeoutError
from playwright.async_api import async_playwright
from telegram_notification import TelegramNotification
# Configuration
with open("linkedin_profiles.txt", "r") as file:
PROFILE_URLS = [line.strip() for line in file.readlines()]
OUTPUT_FILE = "linkedin_profiles_output.json"
SCREENSHOTS_DIR = "linkedin_screenshots"
LI_AT_COOKIE = "LINKEDIN_LI_AT_COOKIE" # Replace with your LinkedIn li_at cookie value
HEADLESS = True # Set to False to see the browser while scraping
PAGE_TIMEOUT = 30000 # 30 seconds timeout for loading
RETRY_DELAY = 3 # Seconds to wait between retries
MAX_RETRIES = 2 # Maximum number of retry attempts
# Configuration section
config = {
"global_config": {
"telegram_bot_token": os.getenv("TELEGRAM_BOT_TOKEN"),
"telegram_chat_id": os.getenv("TELEGRAM_CHAT_ID"),
}
}
class LinkedInScraper:
def __init__(self, li_at_cookie=None, config=None):
self.li_at_cookie = li_at_cookie
self.config = config # Add config parameter for Telegram notifications
self.browser = None
self.context = None
self.page = None
@staticmethod
def sanitize_filename(url: str) -> str:
"""Convert URL to a valid filename"""
parsed = urlparse(url)
path_parts = parsed.path.strip("/").split("/")
profile_id = path_parts[-1] if path_parts else "unknown"
sanitized = re.sub(r'[<>:"/\\|?*]', "_", profile_id)
return sanitized
async def wait_for_content(self, timeout=10000):
"""Wait for the page content to be fully loaded"""
try:
# Wait for any content to appear
await self.page.wait_for_selector(
"body div", # More general selector
timeout=timeout,
state="attached",
)
# Brief delay for any dynamic content
await asyncio.sleep(0.5)
return True
except PlaywrightTimeoutError:
logger.warning("Timeout waiting for page content")
return False
async def take_screenshot(self, url: str, section: str, attempt: int = 0) -> str:
"""Take a screenshot of the current page with retry logic"""
os.makedirs(SCREENSHOTS_DIR, exist_ok=True)
base_filename = self.sanitize_filename(url)
filename = f"{base_filename}_{section}.png"
filepath = os.path.join(SCREENSHOTS_DIR, filename)
try:
# Check if there's any content on the page
content_loaded = await self.wait_for_content()
if not content_loaded and attempt < MAX_RETRIES:
logger.warning(
f"Content not fully loaded, retrying... (attempt {attempt + 1})"
)
await asyncio.sleep(RETRY_DELAY)
return await self.take_screenshot(url, section, attempt + 1)
# Take full page screenshot, scroll first to ensure all content is loaded
await self.page.evaluate("window.scrollTo(0, document.body.scrollHeight)")
await asyncio.sleep(0.5) # Brief pause after scrolling
await self.page.evaluate("window.scrollTo(0, 0)") # Scroll back to top
await self.page.screenshot(path=filepath, full_page=True)
logger.info(f"Saved screenshot: {filepath}")
return filepath
except Exception as e:
logger.error(f"Error taking screenshot: {str(e)}")
if attempt < MAX_RETRIES:
logger.info(f"Retrying screenshot... (attempt {attempt + 1})")
await asyncio.sleep(RETRY_DELAY)
return await self.take_screenshot(url, section, attempt + 1)
return None
async def start_browser(self, headless=True):
"""Initialize the browser session with specific fingerprint settings"""
self.playwright = await async_playwright().start()
self.browser = await self.playwright.chromium.launch(
headless=headless,
args=[
"--disable-dev-shm-usage",
"--disable-blink-features=AutomationControlled",
"--window-size=3440,1440",
],
)
# Configure context with supported fingerprint settings
self.context = await self.browser.new_context(
viewport={"width": 3440, "height": 1440},
user_agent="Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/130.0.0.0 Safari/537.36",
color_scheme="no-preference",
reduced_motion="reduce",
forced_colors="none",
device_scale_factor=1,
is_mobile=False,
has_touch=False,
locale="en-US",
timezone_id="America/Denver",
permissions=["geolocation"],
)
# Add fingerprint properties via JavaScript
await self.context.add_init_script("""
Object.defineProperty(navigator, 'deviceMemory', {
get: () => 8
});
Object.defineProperty(navigator, 'hardwareConcurrency', {
get: () => 12
});
Object.defineProperty(screen, 'colorDepth', {
get: () => 24
});
Object.defineProperty(navigator, 'platform', {
get: () => 'Win32'
});
Object.defineProperty(navigator, 'vendor', {
get: () => 'Google Inc.'
});
Object.defineProperty(screen, 'width', {
get: () => 3440
});
Object.defineProperty(screen, 'height', {
get: () => 1440
});
Object.defineProperty(screen, 'availWidth', {
get: () => 3440
});
Object.defineProperty(screen, 'availHeight', {
get: () => 1440
});
""")
await self.context.add_cookies(
[
{
"name": "li_at",
"value": self.li_at_cookie,
"domain": ".linkedin.com",
"path": "/",
}
]
)
self.page = await self.context.new_page()
self.page.on("pageerror", lambda err: logger.error(f"Page error: {err}"))
self.page.on(
"console", lambda msg: logger.debug(f"Console {msg.type}: {msg.text}")
)
async def close_browser(self):
"""Close all browser resources"""
if self.page:
await self.page.close()
if self.context:
await self.context.close()
if self.browser:
await self.browser.close()
if self.playwright:
await self.playwright.stop()
async def check_login_status(self):
"""Check if we're still logged into LinkedIn"""
try:
# Check for login page redirects or elements
login_selectors = [
"input[name='session_key']", # Email input field
".login__form", # Login form
"button[data-id='sign-in-form__submit-btn']", # Sign in button
".join-form", # Join now form
]
for selector in login_selectors:
if await self.page.locator(selector).count() > 0:
logger.error("Detected LinkedIn logout - session expired")
if self.config:
notification = TelegramNotification(
config=self.config,
current_client="LinkedIn Scraper",
message="⚠️ LinkedIn session expired - script halted. Please update the li_at cookie.",
)
notification.send()
return False
return True
except Exception as e:
logger.error(f"Error checking login status: {e}")
return False
async def navigate_with_retry(self, url: str, attempt: int = 0) -> bool:
"""Navigate to a URL with retry logic and login check"""
try:
response = await self.page.goto(
url,
wait_until="load",
timeout=PAGE_TIMEOUT,
)
# Check login status after navigation
is_logged_in = await self.check_login_status()
if not is_logged_in:
logger.error("Session expired during navigation")
return False
if not response.ok and attempt < MAX_RETRIES:
logger.warning(
f"Navigation failed (status {response.status}), retrying..."
)
await asyncio.sleep(RETRY_DELAY)
return await self.navigate_with_retry(url, attempt + 1)
return response.ok
except Exception as e:
logger.error(f"Navigation error: {str(e)}")
if attempt < MAX_RETRIES:
await asyncio.sleep(RETRY_DELAY)
return await self.navigate_with_retry(url, attempt + 1)
return False
async def capture_profile(self, profile_url: str) -> Dict:
"""Navigate to profile sections and capture screenshots"""
profile_data = {"screenshots": {"experience": None, "education": None}}
try:
profile_id = profile_url.rstrip("/").split("/")[-1]
# Check login status before capturing each section
is_logged_in = await self.check_login_status()
if not is_logged_in:
return profile_data
# Capture experience section
experience_url = (
f"https://www.linkedin.com/in/{profile_id}/details/experience/"
)
if await self.navigate_with_retry(experience_url):
profile_data["screenshots"]["experience"] = await self.take_screenshot(
profile_url, "experience"
)
await asyncio.sleep(2)
# Check login status again before education section
is_logged_in = await self.check_login_status()
if not is_logged_in:
return profile_data
# Capture education section
education_url = (
f"https://www.linkedin.com/in/{profile_id}/details/education/"
)
if await self.navigate_with_retry(education_url):
profile_data["screenshots"]["education"] = await self.take_screenshot(
profile_url, "education"
)
return profile_data
except Exception as e:
logger.error(f"Error capturing LinkedIn profile {profile_url}: {str(e)}")
return profile_data
async def main():
os.makedirs(SCREENSHOTS_DIR, exist_ok=True)
existing_data = {}
if os.path.exists(OUTPUT_FILE):
with open(OUTPUT_FILE, "r") as f:
existing_data = json.load(f)
logger.info(
f"Loaded {len(existing_data)} existing profiles from {OUTPUT_FILE}"
)
scraper = LinkedInScraper(LI_AT_COOKIE, config)
try:
await scraper.start_browser(headless=HEADLESS)
total_profiles = len(PROFILE_URLS)
for idx, profile_url in enumerate(PROFILE_URLS, 1):
if profile_url in existing_data:
logger.info(
f"[{idx}/{total_profiles}] Skipping already processed profile: {profile_url}"
)
continue
try:
logger.info(
f"[{idx}/{total_profiles}] Capturing screenshots for profile: {profile_url}"
)
profile_data = await scraper.capture_profile(profile_url)
# Check if we got logged out during capture
if not await scraper.check_login_status():
break
existing_data[profile_url] = profile_data
with open(OUTPUT_FILE, "w") as f:
json.dump(existing_data, f, indent=2)
successful_screenshots = sum(
1
for screenshot in profile_data["screenshots"].values()
if screenshot
)
if successful_screenshots == 2:
logger.info(
f"[{idx}/{total_profiles}] Successfully captured all screenshots for {profile_url}"
)
else:
logger.warning(
f"[{idx}/{total_profiles}] Captured {successful_screenshots}/2 screenshots for {profile_url}"
)
delay = random.uniform(108, 120)
logger.info(f"Sleeping for {delay:.2f} seconds to mimic human behavior")
await asyncio.sleep(delay)
except Exception as e:
logger.error(
f"[{idx}/{total_profiles}] Error processing {profile_url}: {str(e)}"
)
with open(OUTPUT_FILE, "w") as f:
json.dump(existing_data, f, indent=2)
finally:
await scraper.close_browser()
if __name__ == "__main__":
try:
asyncio.run(main())
except KeyboardInterrupt:
pass
Trying to properly extract the education and job experience text from the detail pages of each person's profile proved... elusive, so I flintstones'd it by grabbing screenshots of the relevant pages and using this script to get Gemini 1.5 Flash 8b to extract the text for me for free:
import json
import os
import time
import google.generativeai as genai
from json_repair import repair_json
# Configuration
API_KEY = "GOOGLE_API_KY"
SCREENSHOTS_DIR = "linkedin_screenshots"
PROFILES_FILE = "linkedin_profiles.txt"
OUTPUT_FILE = "linkedin_analysis_results.json"
# Rate limit configuration
REQUESTS_PER_MINUTE = 2
SECONDS_BETWEEN_REQUESTS = 60 / REQUESTS_PER_MINUTE
# Configure Gemini
genai.configure(api_key=API_KEY)
model = genai.GenerativeModel("gemini-1.5-flash-8b")
def analyze_image(image_path, prompt):
# Upload and analyze the image using Gemini
image_file = genai.upload_file(image_path)
try:
response = model.generate_content([image_file, prompt])
# Repair any malformed JSON in the response
repaired_json = repair_json(response.text)
# Parse the repaired JSON string into a Python dictionary
parsed_data = json.loads(repaired_json)
return parsed_data
except Exception as e:
print(f"Error analyzing image: {e}")
return None
def read_profiles(file_path):
with open(file_path, "r") as file:
return [line.strip() for line in file if line.strip()]
def main():
# Load existing results if they exist
if os.path.exists(OUTPUT_FILE):
with open(OUTPUT_FILE, "r") as f:
try:
results = json.load(f)
except json.JSONDecodeError:
# If the output file is corrupted, try to repair it
with open(OUTPUT_FILE, "r") as f:
results = repair_json(f.read())
else:
results = {}
profiles = read_profiles(PROFILES_FILE)
for profile_url in profiles:
profile_id = profile_url.split("/")[-1]
# Skip if profile was already processed
if profile_id in results:
print(f"Skipping already processed profile: {profile_id}")
continue
results[profile_id] = {
"linkedin_url": profile_url # Store the full LinkedIn URL
}
for section in ["education", "experience"]:
screenshot_path = os.path.join(
SCREENSHOTS_DIR, f"{profile_id}_{section}.png"
)
if os.path.exists(screenshot_path):
prompt = f"Extract the {section} information from this LinkedIn profile screenshot. Output a JSON object with the {section} information."
analysis = analyze_image(screenshot_path, prompt)
if analysis:
results[profile_id][section] = analysis
# Save after each section is processed
with open(OUTPUT_FILE, "w") as f:
json.dump(results, f, indent=4)
time.sleep(SECONDS_BETWEEN_REQUESTS) # Respect rate limits
print(f"Analysis complete. Results saved to {OUTPUT_FILE}")
if __name__ == "__main__":
main()This did a thoroughly respectable job! Ex:
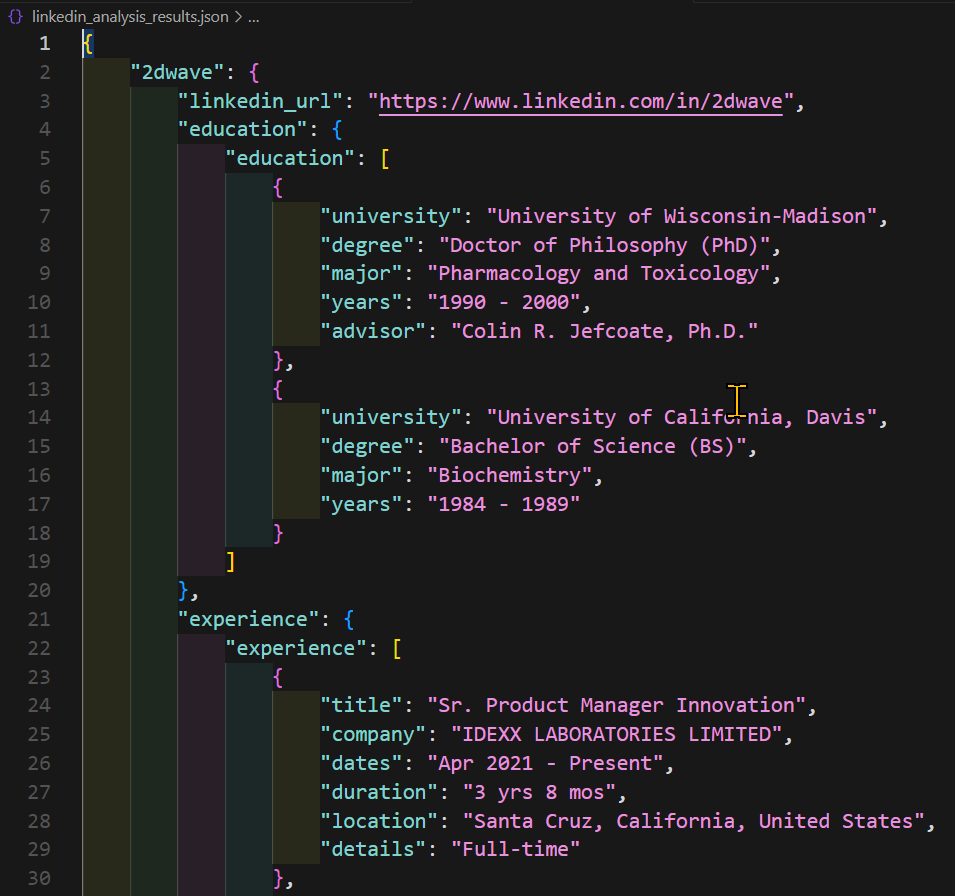
The next step was a few days of low-speed scraping and image-to-text data extraction.
Then, I repeated the whole process again for a cohort 10 years senior to the first group, so that I could do the simplest possible comparison, which is to see what sort of differences these two groups might have between each other. My starting point question for this analysis was: is there a difference in the distribution of job titles between these two cohorts? If so, is it meaningful or interesting in any way?
Stay tuned for part 2...